

How Adfolks helped a large Kuwait based conglomerate build serverless ETL to increase its performance & reduce cost by 10x
The arrival of cloud, SaaS, and big data has led to an explosion in the number of new data sources and streams. To top it, there has been a wider variety of data sources, a greater volume of data, and the need to transfer data at a quicker pace between systems globally. This has led to a surge in demand for more advanced data integration tools that can not only handle the greater volume, velocity, but also a rise in variety. In addition, over time techniques have developed to help solve data integration issues and advance the speed of preparing data for decision support. Many of these enhancements have been made on the on-premise tools, in addition to being able to connect with cloud resources. Meanwhile, ETL tools have also been created and improved in the cloud, which in some cases do a commendable job of managing big data concerns along with linking to cloud resources.
One of the many improvements made to ETL technology is to give real-time or near real-time analytics. Another development is to simplify and reduce the cost of ETL work. This can be accomplished partly by providing or maintaining the infrastructure on which ETL jobs run.
Serverless ETLs are ETLs without provisioning a dedicated server which needs to be maintained and paid through-out even when the job is not running. Serverless is cost-effective because it is per-run cost only also virtually no management of the server itself. The involvement of serverless ETL has the advantage of streamlining the ETL process, such as allowing data developers more time to focus on planning data and constructing data pipelines rather than considerations for not only on-prem but also server-based ETL softwares on cloud as well. Another advantage is a smoother exchange of heterogeneous data sources and data destinations that are already in the cloud. Then there are the additional benefits of serverless code that run on AWS service. Here we can write the code on SQL and this transformation code can be used on a serverless platform. Athena with no cost spent on dedicated servers.
An overview of the project
All these factors and knowledge came into play when I handled a project for one of our esteemed clients, a Kuwait-based family conglomerate. They approached us with a unique problem—the group was looking for a modern ETL platform to process their on-premise data and store it in the cloud, on AWS. Then, Kerridge Autoline was the Dealer Management System that was used by the client.
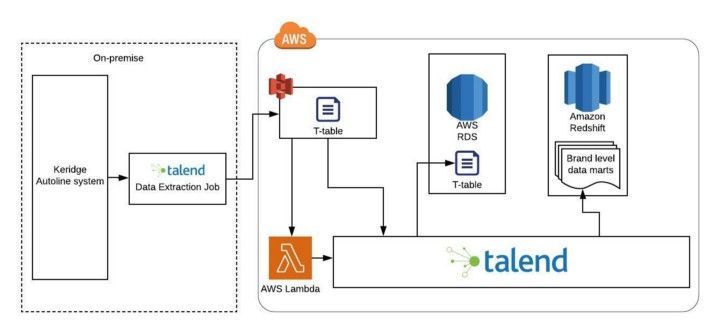
The data from the Kerridge Autoline System needed to be segregated by brands and appended to its destination AWS redshift tables on a daily basis. The group’s Customer Data Platform was consuming from the AWS redshift. At the time, they reached out to us, the client’s team had written scripts to fetch data from the tables in Kerridge Autoline System and write it to S3 with a mix of JDBC/ODBC and Talend for ETL in the workflow. They were on the lookout for a system integrator to support with designing and implementing the scope, which was, perform delta and ETL/ELT on the Kerridge Autoline using Talend Data Fabric and RDS instance as the resilient database, segregate the data by brands and append them to the final redshift table which the CDP system could consume from.
Challenges Faced
When I visited the group’s headquarters in Kuwait to get a clear overview of the problem, they informed me that they intended to use Oracle RDS as a staging database, performing delta operations with all configurations kept on-premise inside of Talend. At that point, as a first approach, I pondered if Oracle DBS, being expensive, was the best solution and mentally made a note of alternative solutions. But before I suggested an alternate solution, I wanted to ensure if a DBC was required or not. The Group had an ETL orchestration that could monitor all jobs while at the same there was no requirement for any complex integration. To get a clear picture, I went to the site and observed their current data loading jobs and business requirements. During my examination, I realized they had planned to use RDS in between data warehouse—essentially, extract, transform, and load, which could cost a lot. Then as a second option, I wondered if the ETL method would work better– extracting, transforming, and loading data to redshift and from there, to carry out to transformation. However, if we went ahead with the ELT approach, there would be a need to increase the sizing of the redshift. There would be a need to have 2.5 times of the particular redshift, which in turn would cost $2000-$5000 dollars.
Proposed Solution
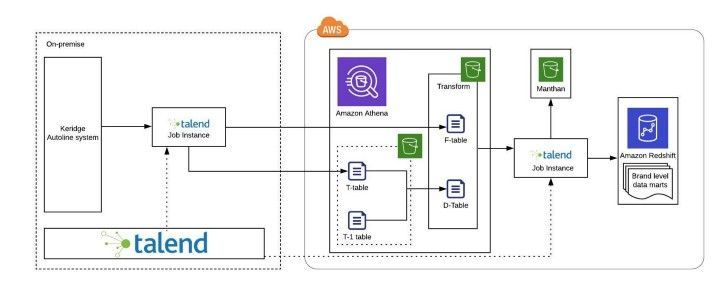
That was when I realized that it would be better to go with the ETL path but taking the serverless approach. So, we proposed to design a solution that could address the problem described above, after analyzing the data transformations required.
We had to use an orchestration tool. Initially, the client wanted to use Talend – but I proposed a more cost-alternative AWS glue, however, the client was insistent on using Talend since they had already acquired its license, which was why I came up with a solution of using ETL on top of Athena, a serverless and interactive query service that was capable of analyzing large -scale datasets using standard SQL. We also proposed the writing of an orchestration data pipeline where it would perform the delta load using Athena. On top of that, it would reduce the cost by 1/10th as well as exponentially increased the performance.
Lessons Learned
During the course of this project, one of the many things that I learned about ETL tools was that an orchestration engine could be one thing. You could have Talend or Informatica, Apache airflow, but based on the needs of the ETL, you could execute different things. Since, for this project, we didn’t have many complex things to carry out during transformation, we decided to go serverless.
Future of this Project
This new approach reduced the company’s cost tenfold, increased performance, and automated the entire ETL process, relying on alerts and telemetry.
One of the high points of this project was that the ETL system we built is totally future proof with auto scalability, i.e. it can easily cope with the rise in the volume of data.##